Trending right now

World Collapse Expert (Ian Bremmer): The Real Crisis Is What Comes After Trump
Is the world on the brink of collapse, and what comes next after a seismic shift in global leadership? Ian Bremmer lays out the stark reality.

Alex Imas on Why Economists Might Be Getting AI Wrong
Are economists miscalculating AI's true impact? Discover why the speed of adoption and job task interconnectedness could reshape our economic future faster than we think.

Our Tax System Should Make You Furious
Is the tax system rigged against you? This episode reveals how the ultra-wealthy pay minimal taxes while you pick up the tab.
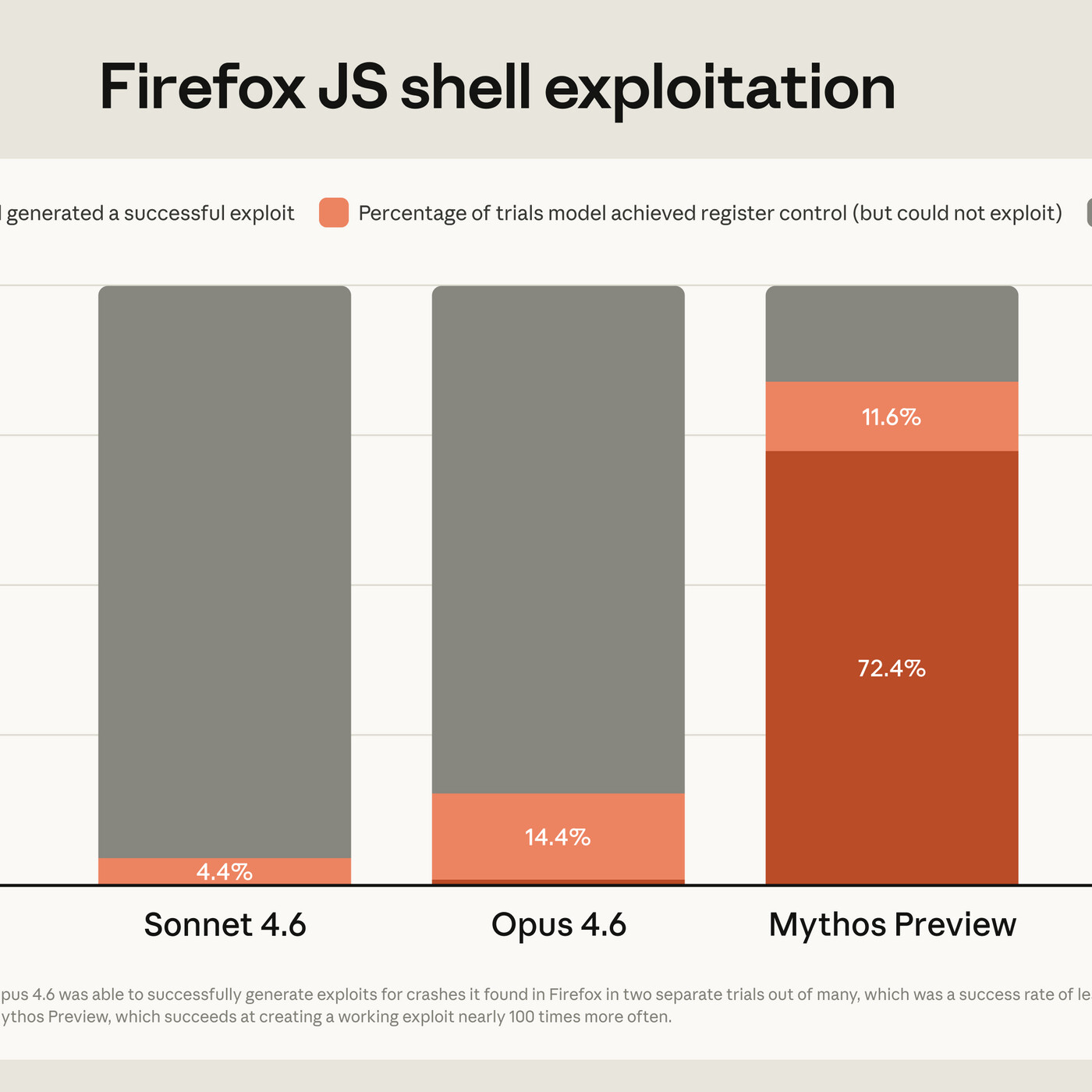
#240 - Project Glasswing, Claude Mythos, GLM-5.1, emotion concepts
From AI finding zero-day vulnerabilities to data centers becoming military targets – the latest AI news is stranger and more critical than fiction.

Gadget Prices Are Getting Ridiculous
Are you feeling the pinch of rising gadget prices? MKBHD dives into why your favorite tech is getting ridiculously expensive.

Data Agents with Shreya Shankar - Weaviate Podcast #135!
- The core challenge for data agents is handling complex, multi-database queries, as existing benchmarks often overlook the reality of diverse data sources.
- AI agents currently perform poorly on data workloads, frequently failing due to an inability to effectively process large datasets and a bias towards simplistic solutions like guessing regular expressions.
- Concepts like semantic operators and declarative systems offer promising ways to bridge the gap between natural language queries and complex data operations, but their effective implementation by AI agents remains an ongoing area of research.
Multi-Vector Search with Amélie Chatelain and Antoine Chaffin - Weaviate Podcast #134!
- Late interaction multi-vector retrieval models offer superior performance for deeper connections and notions of similarity compared to dense models, particularly in domains like code and multimodal data.
- The development of efficient multi-vector retrieval introduces techniques like PLAD (Product Quantization with IVF) and Muvera to approximate complex maximum operations, addressing the computational and storage costs.
- Novel approaches like Colbert Zero demonstrate that training multi-vector models from scratch, skipping expensive unsupervised contrastive steps, can yield state-of-the-art results and significant cost reductions.
Pyversity with Thomas van Dongen - Weaviate Podcast #132!
- Diversification algorithms, particularly DPP (Determinantal Point Process), are recommended as robust and efficient options for improving search and recommendation system results by ensuring result variety.
- The Pyiversity library offers a lightweight, NumPy-dependent Python tool for implementing various diversity strategies, including Maximum Marginal Relevance (MMR), Maximum of Distances (MSD), and DPP, with a focus on speed and ease of integration.
- Diverse retrieval is crucial for LLM-based applications like multi-hop question answering and retrieval-augmented generation (RAG), as it provides broad context without redundancy, preventing performance degradation and enabling more comprehensive AI responses.
Semantic Query Engines with Matthew Russo - Weaviate Podcast #131!
- Semantic query processing engines extend traditional databases by incorporating large language models (LLMs) to enable natural language queries and novel "semantic operators" like filters and joins, moving beyond rigid SQL.
- Optimizing semantic query processing involves balancing LLM processing costs, latency, and result quality, leading to techniques like declarative optimization, model selection, and approximate query processing.
- Sembench aims to be the standard benchmark for semantic query processing, providing a standardized way to test and compare systems across various data modalities and semantic operators.
REFRAG with Xiaoqiang Lin - Weaviate Podcast #130!
- Refra accelerates retrieval-augmented generation (RAG) systems by compressing text chunks into single embeddings, significantly reducing prompt length and inference latency.
- The system employs a multi-stage training approach, including a reconstruction task with curriculum learning, to align encoder and decoder models for effective understanding of compressed chunk embeddings.
- Refra's architecture introduces block-diagonal attention, where only chunk embeddings attend to each other, not the individual tokens within chunks, reducing redundant attention calculations and improving efficiency.
Weaviate and SAS with Saurabh Mishra and Bob van Luijt - Weaviate Podcast #129!
- The evolution of AI from retrieval to RAG to agents reflects a growing need for enterprises to adapt general-purpose language models to their specific, unstructured data.
- Key challenges for AI adoption in enterprises, such as data readiness and security, remain largely unchanged, despite advancements in AI capabilities.
- The development of the SAS Retrieval Agent Manager (RAM) prioritizes flexibility, trustworthiness, rapid time-to-value, and performance to address enterprise needs with a no-code interface and comprehensive evaluation tools.
Weaviate's Query Agent with Charles Pierse - Weaviate Podcast #128!
- The WVA query agent's GA release marks a significant step towards providing a next-generation, natural language interface for database interaction.
- User feedback from the beta release led to key improvements, including the addition of chat functionality and a retrieval-only search mode.
- Schema introspection allows the query agent to leverage database metadata, enabling constrained and structured outputs for more accurate and efficient queries.
GEPA with Lakshya A. Agrawal - Weaviate Podcast #127!
- GPA/Jeppa optimizes AI systems in data-scarce environments by leveraging natural language traces to extract more learning signal from a single rollout compared to traditional methods.
- A key innovation is Pareto-based candidate sampling, which maintains a pool of diverse candidate prompts, each excelling on different task instances, to prevent getting stuck in local optima and ensure domain-specific insights are preserved.
- Japa enables rapid progress thanks to "coarse grain jumps" along the optimization landscape and is positioned to become a text evolution engine for various text components within AI systems to be available in DSP in close proximity to the airing of this podcast.
Agentic Topic Modeling with Maarten Grootendorst - Weaviate Podcast #126!
- Martin discusses the benefits of authoring a book with a publisher like O'Reilly, emphasizing collaboration and quality control over the typical solo blog post approach.
- The conversation delves into the modularity of BERT topic and its evolution with LLMs, highlighting the potential of combining embedding-based methods with the strengths of LLMs while considering the cost and efficiency of reprocessing documents.
- The podcast explores the challenge of evaluating topic modeling subjectively, especially concerning topic granularity, and the need for user-driven approaches with "human in the loop" agentic frameworks to steer results based on specific use cases.
Sufficient Context with Hailey Joren - Weaviate Podcast #125!
- The core idea of sufficient context differs from relevance by evaluating if a model should be able to answer a question given the provided context, considering nuance like multi-hop reasoning.
- The research surprisingly found that smaller models struggle to use available context, while all models are less likely to abstain when given additional context, even if it's insufficient.
- Fine-tuning models to restore the ability to abstain after adding retrieval augmentation (RAG) proved difficult, though the surprising effectiveness of fine-tuning only a small number of parameters suggests unlocking latent capabilities rather than teaching new information.